Compiler 6 中间代码生成
中间代码生成¶
中间代码/中间表示 (Intermediate Representation, IR)¶
AST -> IR1 -> IR2 -> ... -> IRk -> asm
IR 是一种抽象的机器语言、旨在表达目标机器的操作而不涉及过多与指令集有关的细节。相比于直接生成目标架构的汇编语言代码,将源代码首先转为 IR 能够有效地提高编译器的模块化以及可移植性(考虑需要将高级语言转为不同目标架构的汇编语言)。
实际的编译器可能使用多层 IR 以支持不同层次的分析和变换(例如在 gcc 编译器中,涉及的 IR 有 AST(如果将 抽象语法树也看做某种意义上的 IR)、Generic、Gimple、RTL)。添加高层中间表示的一个好处是,对于不同高级语言时,可以复用已有 IR 及其底层优化。
依据 IR 的结构特征,可以分为:Structural(结构化的,例如树、DAG)、Linear(其存储布局是线性的,例如三地址码)、Hybrid(混合的,例如控制流图 CFG,其中节点内部是 Linear,节点之间是 Structural)。
三地址码(Three-Address Code)¶
x = y op z,每条指令指令至多 1 个运算符、3 个操作数。
静态单赋值(Static Single Assignment, SSA)¶
特殊的三地址码,其所有变量在代码中只能被赋值一次。
Tiger 语言的中间代码生成¶
Tiger 语言只使用一个名为 Tree 的 IR,即 AST -> Tree -> asm。
Tree 中的表达式与声明¶
虎书 p.153 - p.154。
IR Tree 将语句分为表达式(expression)和声明(statement),表达式代表某个值的计算(可能有刻意的副作用),声明则负责执行副作用和改变控制流。
表达式的各个可选语句如下表所示:
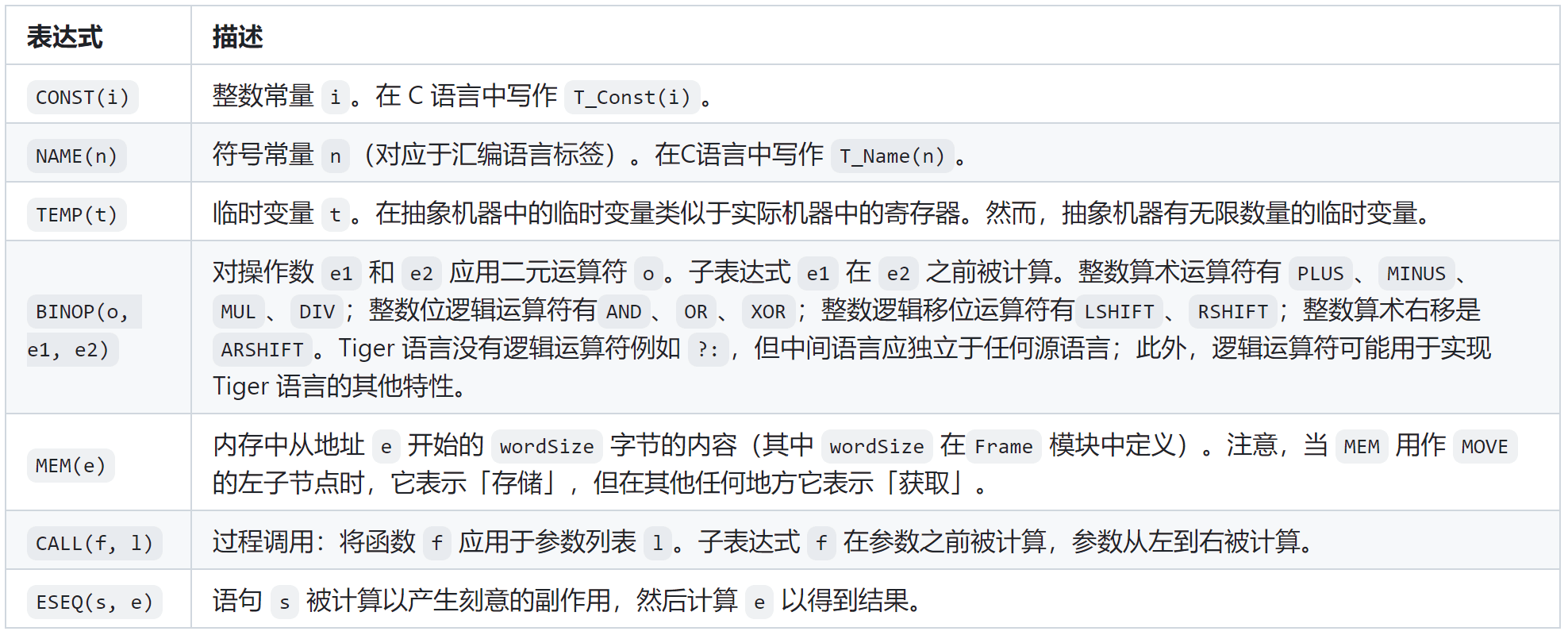
声明的各个可选语句如下表所示:
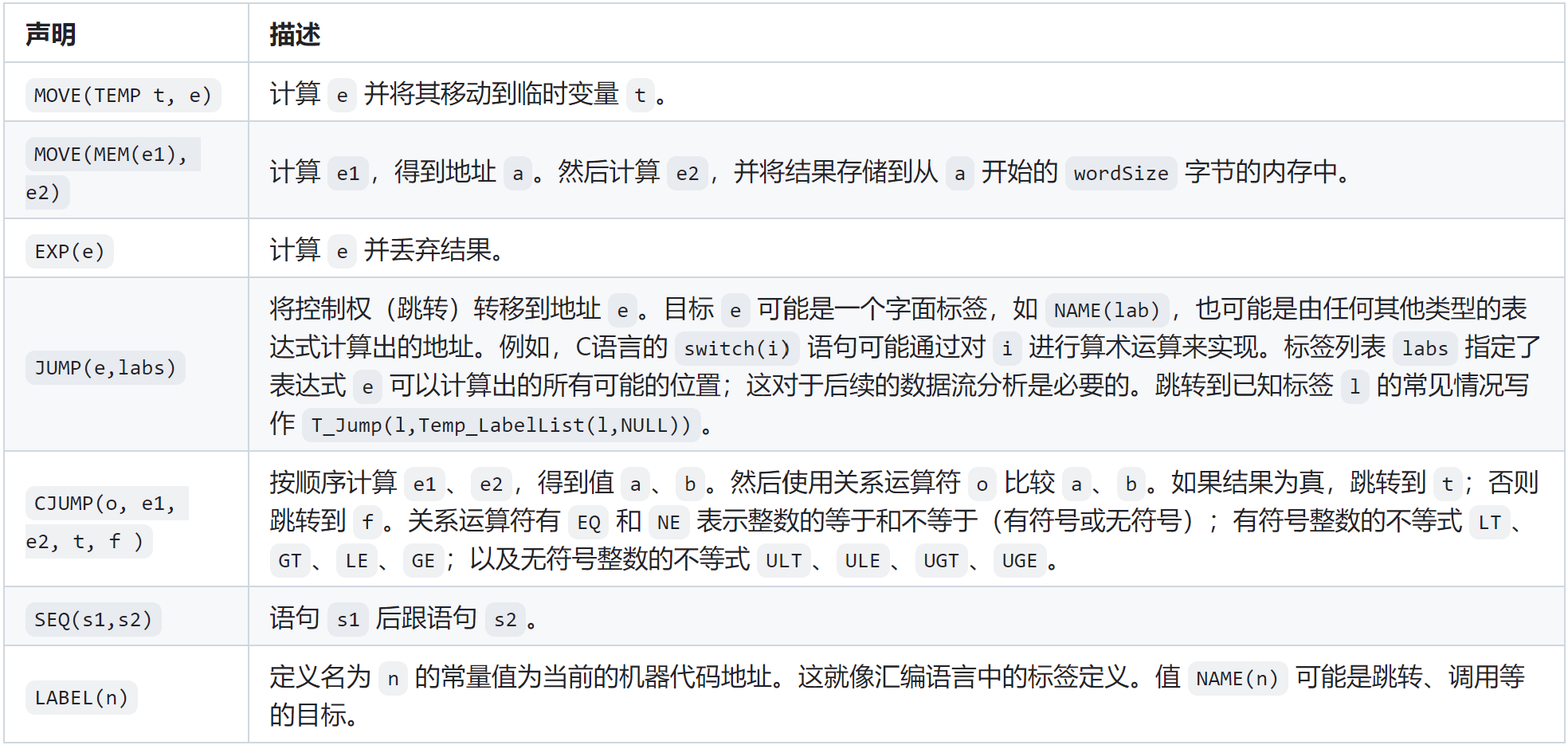
从 Tiger AST 到 IR Tree¶
/* in translate.c */
struct Cx {patchList trues; patchList falses; T_stm stm;};
struct Tr_exp_ {
enum {Tr_ex, Tr_nx, Tr_cx} kind;
union {T_exp ex; T_stm nx; struct Cx cx;} u;
};
static Tr_exp Tr_Ex(T_exp ex);
static Tr_exp Tr_Nx(T_stm nx);
static Tr_exp Tr_Cx(patchList trues, patchList falses, T_stm stm);
在 IR Tree 中,Tiger 的语句被分为三种类型,并对这三种类型有不同的处理方式:
Tr_ex:表达式,计算并返回一个值,表示为Tr_exp。Tr_nx:无结果,表达式执行操作但不返回任何值,表示为T_stm。Tr_cx:条件,表示为可能跳转到不同标签的语句,但这些标签尚未填充。如果填入 true 和 false 对应的跳转目的地址,那么结果语句会对条件进行求值,然后跳转到其中一个目标。
翻译过程¶
基于结构归纳法,详见虎书 p.158 - p.173。
处理 IR¶
IR Tree 包含与真实的汇编语言差异较大的语句,例如 CJUMP, ESEQ, CALL,不便于后续的指令选择。
具体而言,IR Tree 中的 CJUMP(e, t, f) 可以跳转到两个标签(t 与 f 分别对应表达式 e 的真值),而真实的汇编语言一般只能跳转到一个标签。
IR Tree 中的 CALL 对返回值没有指定处理,例如 BINOP(PLUS, CALL(...), CALL(...)),第二个 CALL 的返回值会覆盖寄存器 RV 中第一个 CALL 的返回值。当处理包含函数调用的表达式时,需要考虑函数调用返回值的管理。
IR Tree 中的 ESEQ,例如 BINOP(PLUS, TEMP a, ESEQ(MOVE(TEMP a, u), v)),如果处理的顺序不正确,ESEQ 可能非预期地影响 a 的值。
Canonical Form IR¶
Canonical Tree 被定义为具有以下属性:
- 没有
SEQ或ESEQ节点:规范树中的根节点是唯一的语句节点(如MOVE或EXP),而其他节点都是表达式节点(如BINOP、MEM、CALL等)。这样保证了树的结构更加简洁和明确。 - 每个
CALL节点的父节点要么是EXP(...)节点,要么是MOVE(TEMP t, ...)节点:CALL节点不能嵌套在其他表达式中,必须直接成为根节点的子节点。同时,根节点必须是EXP(...)或MOVE(TEMP t, ...),这两者之一。这样设计是为了确保CALL的副作用(例如修改全局状态)能够被明确控制和管理。
需要将 IR 转化(线性化)为 Canonical Form IR。
- 将树重写为没有
SEQ或ESEQ节点的规范树列表 - 将这个列表分组为一组基本块,它们不包含内部跳转或标签
- 将基本块排序为一组轨迹(traces),其中每个
CJUMP后面紧跟着它的 false 标签
消除 ESEQ¶
将 ESEQ 通过恒等变换,在树中逐渐提升至根节点,直到它们可以成为 SEQ 节点。
恒等变换规则:
ESEQ(s1, ESEQ(s2, e))->ESEQ(SEQ(s1,s2), e)BINOP(op, ESEQ(s, e1), e2)->ESEQ(s, BINOP(op, e1, e2))MEM(ESEQ(s,e1))->ESEQ(s, MEM(e1))JUMP(ESEQ(s, e1))->SEQ(s, JUMP(e1))CJUMP(op, ESEQ(s, e1), e2, l1, l2)->SEQ(s, CJUMP(op, e1, e2, l1, l2))
语句和表达式的可交换性¶
如果 s 不影响 e 的值,则语句 s 和表达式 e 是可交换的。例如,如果 t1 != t2,那么语句 MOVE (MEM(t1), e) 和 MEM(t2) 是可交换的。
如果语句 s 和表达式 e 不可交换,那么就能需要新的临时变量来存储中间结果以获得Canonical Tree。
考虑 BINOP(op, e1, ESEQ(s, e2)):
如果 s 不影响 e1 的值,即 s 和 e1 可交换,那么它等价于 ESEQ(s, BINOP(op, e1, e2))。
如果 s 和 e1 不可交换,那么它等价于 ESEQ(MOVE(TEMP t1, e1), ESEQ(s, BINOP(op, TEMP t1, e2)))。
问题:为什么 BINOP(op, ESEQ(s, e1), e2) -> ESEQ(S, BINOP(op, e1e2)) 不需要考虑 s 和 e2 的可交换性,而 BINOP(op, e1, ESEQ(S, e2)) 则要考虑 s和 e1 的可交换性?
这是因为 BINOP(op, e1, e2) 对 e1 和 e2 的运算顺序是从左往右计算的。对于第一种情况,考虑 s 的影响在求值 e1 和 e2 之前。而对于第二种情况,考虑 s 的影响则是在求值 e1 和 e2 之间。就可能会出现 s 实际上只影响 e2 但没有影响 e1,但如果直接提升 ESEQ 至 BINOP 外侧,则 s 非预期地同时影响了 e1 和 e2 的值。
恒等变换规则(续):
- 如果语句
s和表达式e1可以交换,BINOP(op, e1, ESEQ(s, e2))->ESEQ(s, BINOP(op, e1, e2)) - 如果语句
s和表达式e1不可交换,BINOP(op, e1, ESEQ(s, e2))->ESEQ(MOVE(TEMP t1, e1), ESEQ(s, BINOP(op, TEMP t1, e2))) - 如果语句
s和表达式e1可以交换,CJUMP(op, e1, ESEQ(s, e2), l1, l2)->SEQ(s, CJUMP(op, e1, e2, l1, l2)) - 如果语句
s和表达式e1不可交换,CJUMP(op, e1, ESEQ(s, e2), l1, l2)->SEQ(MOVE(TEMP t1, e1), SEQ(s, CJUMP(op, TEMP t1, e2, l1, l2)))
语句和表达式的可交换性的确定¶
TODO
Moving CALLs to Top Level¶
当处理包含函数调用的表达式时,需要考虑函数调用返回值的管理。
函数调用的返回值通常会分配给一个专用的返回值寄存器,以减少内存 I/O 。当多个 CALL 表达式在同一个上下文中使用时,可能会出现寄存器覆盖的问题。
解决方案是将每个 CALL 的返回值立即分配给一个新的临时寄存器。
CALL(fun, args)->ESEQ(MOVE(TEMP t, CALL(fun, args)), TEMP t)
Moving
CALLs to Top Level 指的是将CALL的副作用和结果显式地分离并在语句层面处理,而不是嵌套在复杂的表达式内部。
消除 SEQ¶
执行完以上两个步骤,IR Tree 的形式应该是形如 SEQ(SEQ(SEQ(..., sx), sy), sz) 的。
反复利用恒等变换 SEQ(SEQ(a, b), c) = SEQ(a, seq(b, c)),可以让 IR Tree 的形式变为 SEQ(s_1, SEQ(s_2, ..., SEQ(s_{n-1}, s_n)...)),这直接对应了汇编语句 s_1, s_2, ..., s_{n-1}, s_n。
基本块 (Basic Blocks) & 轨迹 (Traces)¶
处理 CJUMP(cond, lt, lf),使之能够翻译为大多数汇编语言所支持的只有一个目标的的跳转指令。需要重新排列 IR,使得每个 CJUMP 的 false 标签紧跟在 CJUMP 之后(出于性能优化的考虑)。
对于经过处理的规范树列表,首先将树转换为基本块,然后将所有基本块用轨迹标记。
一个「基本块」是执行过程中顺序执行的一系列指令,第一个语句是 LABEL,最后一个语句是 JUMP 或 CJUMP ,除此之外,基本块的内部没有 LABEL, JUMP 或 CJUMP。
一个「轨迹」是执行过程中顺序执行的不循环的一系列基本块。
将 IR 序列转换为基本块:
- 从头到尾扫描 IR 的语句。
- 当找到标签时,开始一个新基本块(并结束前一个基本块)。
- 当找到条件跳转(
CJUMP)或跳转(JUMP)时,结束当前基本块(并开始下一个基本块)。 - 如果基本块结束时没有
CJUMP或JUMP,则在其后附加跳转到下一个基本块的指令。 - 如果基本块开头没有标签,则为其生成一个标签并添加上去。
将所有基本块用轨迹覆盖,以减少不必要的跳转,对 CFG 使用深度优先搜索1:

最后,调整 CJUMP 后面紧跟的标签:
- 如果
CJUMP后跟着的标签是 true 标签,互换 true 和 false 标签,并对条件取反。 - 如果
CJUMP后跟着的标签是 false 标签,什么都不做。 - 如果
CJUMP后跟着的标签既不是 true 标签,也不是 false 标签,替换CJUMP(cond, a, b, lt, lf)为:
-
src: Tiger p.187 ↩